IO模型
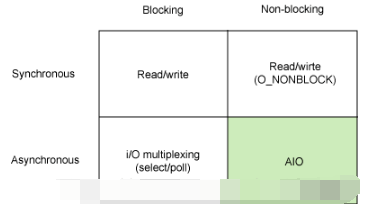
用一幅图表示所支持的I/O模型
纵向维度是“阻塞(Blocking)”、“非阻塞(Non-blocking)”;横向维度是“同步”、“异步”。总结起来是四种模型同步阻塞、同步非阻塞;异步阻塞、异步非阻塞。《Unix网络编程》中划分出了“第五种”模型——“信号驱动式IO”其实属于异步阻塞类型,这种模型的通知方式有多种多样后面展开说明。
同步/异步、阻塞/非阻塞
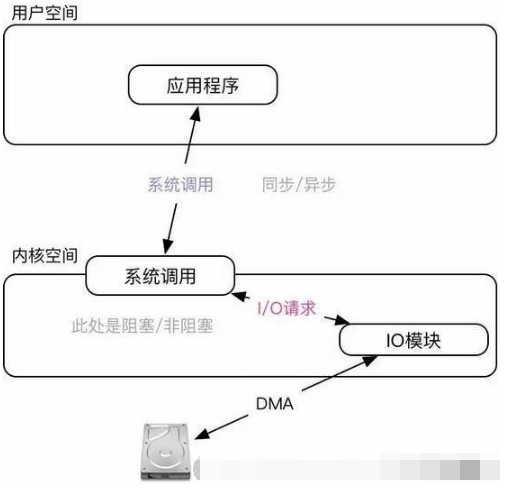
从内核角度看I/O操作分为两步:用户层API调用;内核层完成系统调用(发起I/O请求)。所以“异步/同步”的是指API调用;“阻塞/非阻塞”是指内核完成I/O调用的模式。用一幅图表示更加明显
同步是指函数完成之前会一直等待;阻塞是指系统调用的时候进程会被设置为Sleep状态直到等待的事件发生(比如有新的数据)。明白这一点之后再看这五种模型相信就会清晰很多,我们挨个分析:
同步阻塞
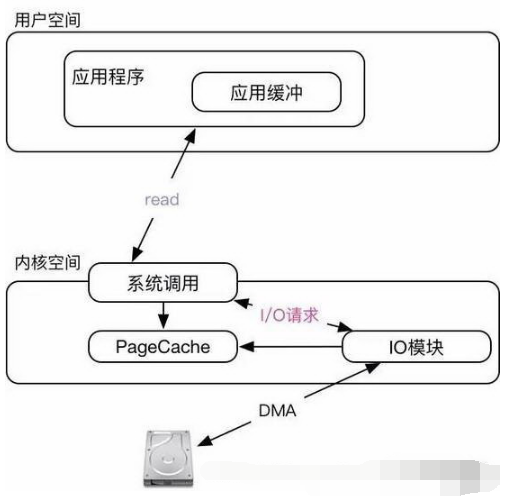
这种模型最为常见,用户空间调用API(read、write)会转化成一个I/O请求,一直等到I/O请求完成API调用才会完成。这意味着:在API调用期间用户程序是同步的的;这个API调用会导致系统以阻塞的模式执行I/O,如果此时没有数据则一直“等待”(放弃CPU主动挂起——Sleep状态)(注意,对于硬盘来说是不会出现阻塞的,无论是什么时候读它总是有数据。常见的阻塞设备是终端、网卡之类的)。
以read为例子,它由三个参数组成,第一个函数是文件描述符;第二个是应用缓冲;第三个参数是需要读取的字节数。经过系统调用会以阻塞模式执行I/O,I/O模块读取数据后会放入到PageCache中;最后一步是把数据从PageCache复制到应用缓冲。如果I/O请求无法得到满足——没有数据,则主动让出CPU直到有数据(注意,即便系统调用让出CPU也未必真的就让出。read函数是同步的,所以CPU还是会被用户空间代码占用)。
同步非阻塞
这种模式通过调用read、write的时候指定O_NONBLOCK参数。和“同步阻塞”模式的区别在于系统调用的时候它是以非阻塞的方式执行,无论是否有数据都会立即返回。以read为例,如果成功读取到数据它返回读取到的字节数;如果此时没有数据则返回-1,同时设置errno为EAGAIN(或者EWOULDBLOCK,二者相同)。所以这种模式下我们一般会用一个“循环”不停的尝试读取数据,处理数据。
异步阻塞
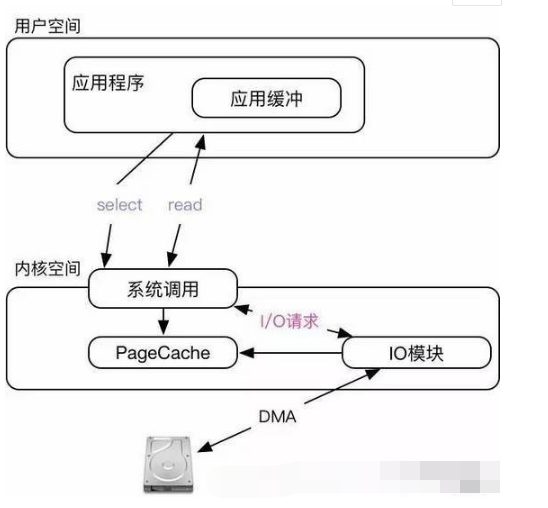
同步模型最主要的问题是占用CPU,阻塞I/O会主动让出CPU但是用户空间的系统调用还是不会返回依然耗费CPU;非阻塞I/O必须不停的“轮询”不断尝试读取数据(会耗费更多CPU更加低效)。如果仔细分析同步模型霸占CPU的原因不难得出结论——都是在等待数据到来。异步模式正是意识到这一点所以把I/O读取细化为订阅I/O事件,实际I/O读写,在“订阅I/O事件”事件部分会主动让出CPU直到事件发生。异步模式下的I/O函数和同步模式下的I/O函数是一样的(都是read、write)唯一的区别是异步模式“读”必有数据而同步模式则未必。常见的异步阻塞函数包括select,poll,epoll,这些函数的用法需要花费相当大的篇幅介绍而这篇文章我想集中精力介绍“I/O模型”。以select为例我们看一下大致原理
异步模式下我们的API调用分为两步,第一步是通过select订阅读写事件这个函数会主动让出CPU直到事件发生(设置为Sleep状态,等待事件发生);select一旦返回就证明可以开始读了所以第二部是通过read读取数据(“读”必有数据)。
异步阻塞模型之信号驱动
“完美主义者”看了上面的select之后会有点不爽——我还要“等待”读写事件(即便select会主动让出CPU),能不能有读写事件的时候主动通知我啊?。借助“信号”机制我们可以实现这个,但是这并不完美而且有点弄巧成拙的意思。具体用法:通过fcntl函数设置一个F_GETFL|O_ASYNC(曾经信号驱动I/O也叫“异步I/O”所以才有O_ASYNC的说法),当有I/O时间的时候操作系统会触发SIGIO信号。在程序里只需要绑定SIGIO信号的处理函数就可以了。但是这里有个问题——信号处理函数由哪个进程执行呢?,答案是:“属主”进程。操作系统只负责参数信号而实际的信号处理函数必须由用户空间的进程实现。(这就是设置F_SETOWN为当前进程PID的原因)信号驱动性能要比select、poll高(避免文件描述符的复制)但是缺点是致命的——*Linux中信号队列是有限制的如果操过这个数字问题就完全无法读取数据。
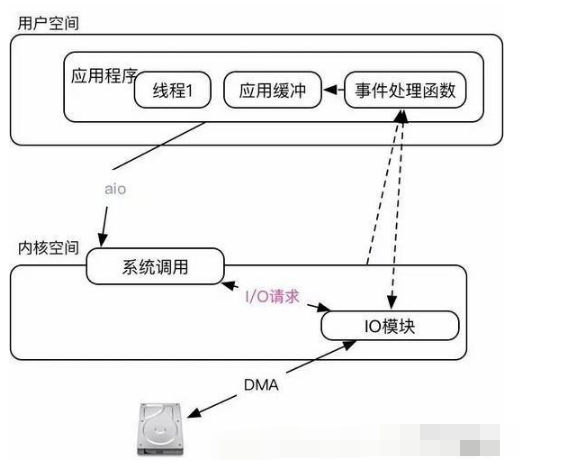
异步非阻塞
这种模型是最“省事”的模型,系统调用完成之后就只要坐等数据就可以了。是不是特别爽?其实不然,问题出在实现上。Linux上的AIO两个实现版本,POSIX的实现最烂(蓝色巨人的锅)性能很差而且是基于“事件驱动”还会出现“信号队列不足”的问题(所以它就偷偷的创建线程,导致线程也不可控了);一个是Linux自己实现的(redhat贡献)NativeAIO。NativeAIO主要涉及到的两个函数io_submit设置需要I/O动作(读、写,数据大小,应用缓冲区等);io_getevents等待I/O动作完成。没错,即便你的整个I/O行为是非阻塞的还是需要有一个办法知道数据是否读取/写入成功。
注意图中,内核不再为I/O分配PageCache,所有的数据必须有用户自己读取到应用缓冲中维护。所以AIO一定是和“直接I/O”配合使用。AIO针对网卡设备的意义不大,首先它的实现本质上和epoll差不多;其次它在Linux中的作用更多的是用于磁盘I/O(异步非阻塞可以不用多线程就造成大量的I/O请求便于I/O模块“合并”优化会提高整体I/O的吞吐率——而且对CPU开销比较少)。在Nginx中用了一个技巧,可以实现AIO和epoll联动,AIO读取到数据后触发epoll发送数据。(这个特性是非常尴尬的,如果是磁盘文件完全可以用sendfile搞定)。
DirectI/O和BufferedI/O
Linux在进行I/O操作的时候会先把数据放到PageCache中然后通过“内存映射”的方式返回给应用程序,这样做的好处是可以预读数据也能在多个进程读取相同数据的时候起到Cache的作用。应用程序不能直接使用PageCache中的数据,通常是复制到一块“用户空间”的内存中再使用。
●DirectI/O是指数据不落在PageCache,直接从设备读取到数据后放到用户空间中
●BufferedI/O是指数据竞购PageCache
同步I/O只能使用BufferedI/O;异步阻塞I/O可以BufferedI/O也可以使用DirectI/O;异步非阻塞I/O只能使用DirectI/O
ZeroCopy
考虑从磁盘读取文件经过网卡发送出去,会有四次内存复制:1.DMA会复制磁盘数据到内核空间,2.应用程序复制内核空间的数据到用户空间;3.应用程序用户空间的数据复制到Socket缓冲(内核空间);4.协议栈把数据复制到网卡的中发送。简单来说ZeroCopy就是节省这个过程中的内存复制次数。有几种做法:
●DirectI/O直接把磁盘数据复制到内核空间;但是DirectI/O没有办法直接把数据放到网卡中——必须要经过协议栈。所以可以节省一次内存复制;
●sendfile,磁盘数据通过DMA读取到内核空间后直接交给TCP/IP协议栈;真正的不需要内存复制;
除此之外还可以利用splice、mmap做一些优化,根据不同的设备需要采用不同的方式此处不再展开。
原文链接:https://blog.csdn.net/caohao1210/article/details/78323151